[SQL]SQL로 타이타닉 생존자 예측하기
📑 서론
🚢 M/L 입문 필수 타이타닉 생존자 예측
📌 SQL, PL/SQL 로 머신러닝 하기
머신러닝 입문으로 많이 접하는 타이타닉 생존자 예측을 SQL과 PL/SQL을 사용해서 진행해 보았다.
Oracle db를 사용했고, sqldeveloper로 진행하였다.
📝 사용 데이터
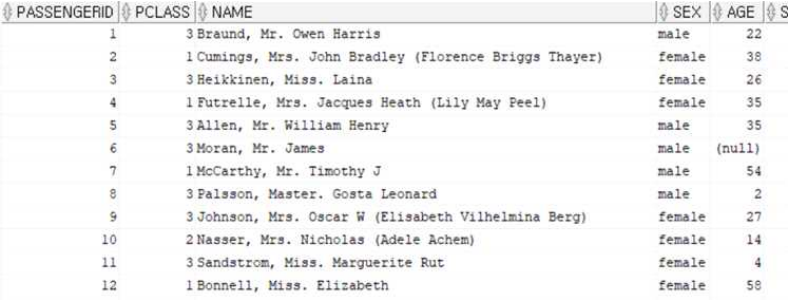
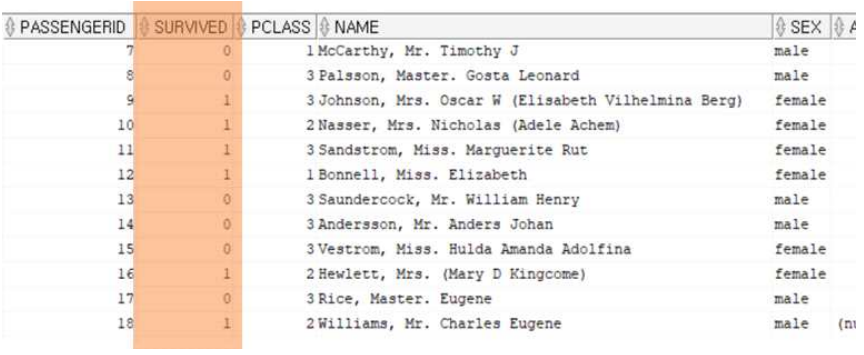
titanic: Machine Learning from Disaster (승객 데이터 총 891건 으로 구성)
📑test.csv -> survived(생존여부) 컬럼이 없음. (해당 테이블에서 생존여부 예측)
📑train.csv -> survived(생존여부) 컬럼이 있음. (해당 테이블을 이용하여 데이터정제, 예측지표, 파생변수 생성)
데이터 출처 : http://kaggle.com/c/titanic <kaggle(캐글)>
📑test.csv
📑train.csv
⛏ 데이터 확인 및 전처리
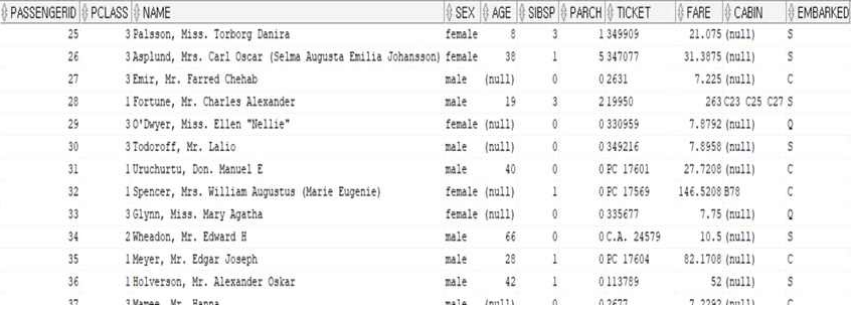
1. 데이터 확인
SELECT *
FROM train;
🧮 컬럼설명
| 컬럼 | 설명 |
|---|---|
| PASSENGERID | 승객번호 |
| SURVIVED | 생존여부 (0:사망, 1:생존) |
| PCLASS | 좌석등급 (1:1등석, 2:2등석, 3:3등석) |
| NAME | 이름 |
| SEX | 성별 (female:여성, male:남성) |
| AGE | 나이 |
| SIBSP | 함께 탑승한 형제 또는 배우자의 수 (Number of Siblings/Spouses) |
| PARCH | 함께 탑승한 부모 또는 자녀의 수 (Number of Parents/Children) |
| TICKET | 티켓번호 |
| FARE | 티켓요금 |
| CABIN | 선실 번호 |
| EMBARKED | 탑승한 곳 (C:Cherbourg, Q:Queenstown, S:Southampton) |
2. 데이터 전처리
1. 생존, 사망 여부에 연관성이 적거나 없다고 판단되고 결측치(NULL)가 많아 판단이 어려운 컬럼 제거
2. SIBSP, PARCH 컬럼의 데이터를 병합해 동승가족수 컬럼 생성
3. NAME에 포함된 신분정보를 추출하여 신분 컬럼 생성
4. AGE의 결측치(NULL)를 3번에서 만든 신분 데이터를 이용하여 유추하여 보간
5. AGE를 이용해서 연령대별(미성년, 청년, 장년, 중년, 노년 5단계 분할) 컬럼 생성
2.1. 생존, 사망 여부와 연관성 판단이 어려운 컬럼 제거
- TICKET(티켓번호)
- CABIN(선실번호)
- FARE(티켓요금)
- EMBARKED(탑승장소)
1) TICKET(티켓번호)
SELECT TICKET
FROM train;
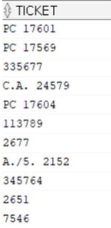
생존 여부에 전혀 연관이 없다고 판단
👉 컬럼 제거
ALTER TABLE train
DROP COLUMN TICKET;
2) CABIN(선실번호)
SELECT CABIN
FROM train;
생존 여부에 연관이 있으나 결측치(NULL)가 많아 판단이 어려움
👉 컬럼 제거
ALTER TABLE train
DROP COLUMN CABIN;
3) FARE(티켓요금)
금액에 따른 생존여부 연관성 판단을 위해 요금지불 순위와 생존여부 확인
SELECT MAX(FARE) AS 최고요금, MIN(FARE) AS 최저요금
FROM train;
SELECT FARE, SURVIVED, RANK() OVER(ORDER BY FARE DESC) AS 요금지불순위
FROM train;
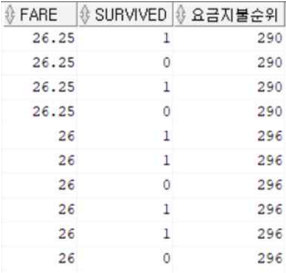
요금지불순위가 낮음에도 불구하고 생존여부에는 큰 상관이 없는 것으로 확인 됨
👉 컬럼 제거
ALTER TABLE train
DROP COLUMN FARE;
4) EMBARKED(탑승장소)
각 탑승장소의 생존/사망자 수 확인
SELECT EMBARKED, SURVIVED, COUNT(*)
FROM train
GROUP BY ROLLUP(EMBARKED, SURVIVED);
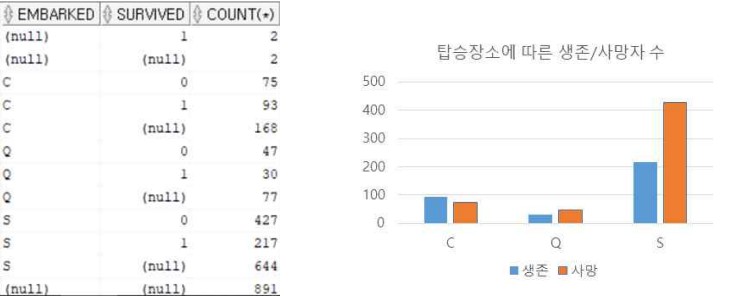
탑승장소에 따른 생존여부 연관성 확인이 어려움
S(Southampton)에서 탑승한 승객들이 대체로 많이 사망했으나 다른 장소와 인원 수 대비 비교가 어려움
👉 컬럼 제거
ALTER TABLE train
DROP COLUMN EMBARKED;
2.2. 동승가족수 컬럼 생성
SIBSP(함께 탑승한 형제/배우자의 수), PARCH(함께 탑승한 부모/자녀의 수)
👉 두 개의 컬럼을 동승가족수 라는 하나의 컬럼으로 병합하여 파생변수 생성
MERGE INTO train2 t2
USING train t1
ON(t2.NAME = t1.NAME)
WHEN MATCHED THEN
UPDATE SET t2.동승가족수 = t1.SIBSP+t1.PARCH;

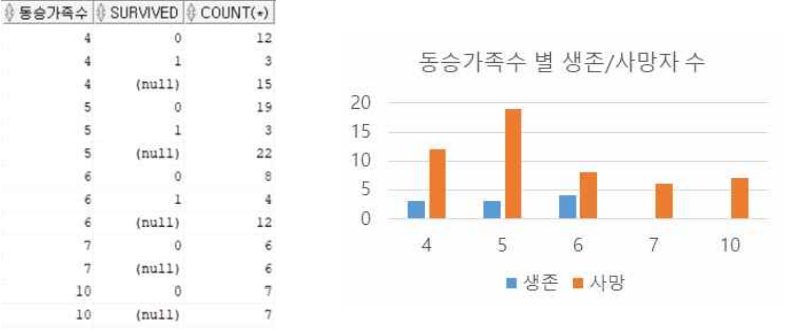
SELECT 동승가족수, SURVIVED, COUNT(*)
FROM train2
GROUP BY ROLLUP(동승가족수, SURVIVED);
2.3. 신분 컬럼 생성
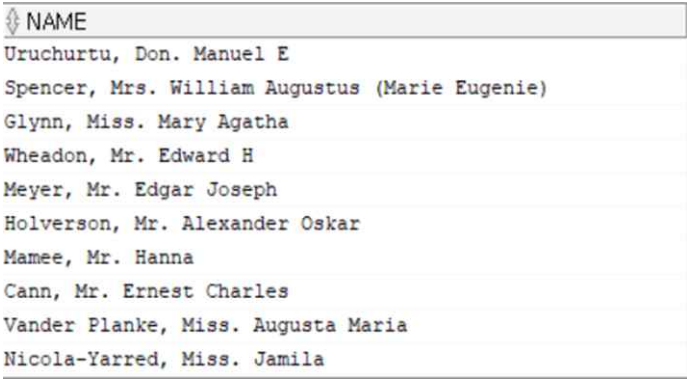
NAME(이름) 데이터 자체만으로는 생존여부와 연관성 파악이 어렵지만, 이름에 포함된 신분(Mr, Mrs, Miss 등)은 생존여부와 연관이 있을 것 이라고 판단
👉 이름에서 신분정보만 추출하여 신분 컬럼 생성
// 이름 데이터에서 신분만 추출한 컬럼을 포함한 View 생성
CREATE VIEW PASSENGER_STATUS
AS
SELECT NAME, SUBSTR(TRIM(REGEXP_SUBSTR(NAME,'[[:punct:]][[:blank:]][[:alpha:]]+')),3) AS 신분
FROM train;
SELECT * FROM PASSENGER_STATUS;
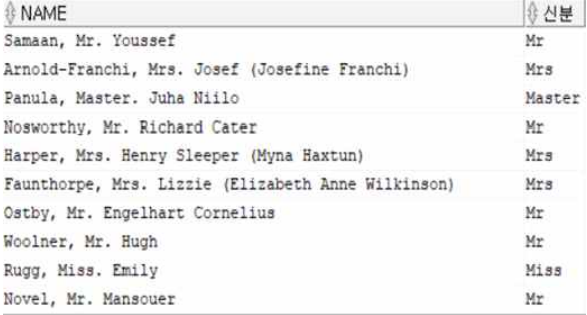
// 신분 컬럼을 생성하고 View를 이용하여 Update
ALTER TABLE train2
ADD 신분 VARCHAR2(15);
MERGE INTO train2 t
USING PASSENGER_STATUS ps
ON(t.name = ps.name)
WHEN MATCHED THEN
UPDATE SET t.신분 = ps.신분;
// 신분 컬럼 생성으로 불필요해진 이름 컬럼 제거
ALTER TABLE train2
DROP COLUMN NAME;

2.4. AGE(나이) 결측치(NULL) 보간
AGE(나이)가 NULL인 사람들의 신분별 인원 수
SELECT 신분, COUNT(*) AS 인원수
FROM train2
WHERE AGE IS NULL
GROUP BY ROLLUP(신분);
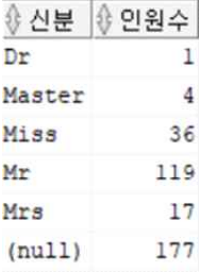
나이가 NULL인 177명의 승객의 나이를 위에서 생성한 신분 데이터로 보간
AGE(나이)가 실수형인 데이터가 존재 -> 정수로 변환
// AGE(나이)가 실수형인 데이터가 존재 -> 정수로 변환
UPDATE train2
SET AGE = CEIL(AGE);
// commit
COMMIT;
성별, 신분별로 구분했을 때의 나이지표 확인
// 성별
--남성
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE sex ='male';
--여성
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE sex ='female';

// 신분별
--Dr
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE 신분 ='Dr';
--Master
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE 신분 ='Master';
--Miss
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE 신분 ='Miss';
--Mr
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE 신분 ='Mr';
--Mrs
SELECT min(age) AS 최소나이, max(age) AS 최대나이, round(avg(age)) AS 평균나이, median(age) AS 중앙나이
FROM train2
WHERE 신분 ='Mrs';
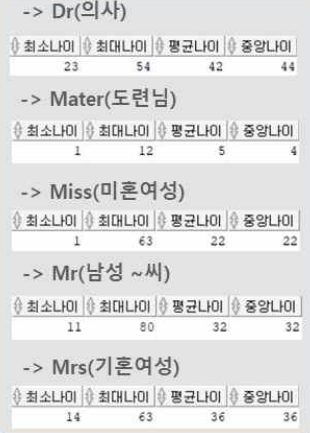
신분별로 확인한 나이지표가 더 구체적으로 신뢰할 수 있음.
👉 각 신분의 평균나이로 보간
begin
for i in (select t.*, a.신분평균
from train2 t,(select 신분, round(avg(age)) 신분평균
from train2
group by 신분) a
where t.신분 = a.신분)loop
if i.age is null then
update train2
set age = i.신분평균
where passengerid = i.passengerid;
end if;
end loop;
end;
/
2.5. 나이로 연령대별(미성년, 청년, 장년, 중년, 노년 5단계로 분할) 컬럼 생성
나이의 결측치를 각 신분의 평균나이로 보간했지만 나이별 생존, 사망의 연관성 파악을 더 효율적으로 하기 위해 나이를 구간대별 연령대로 그룹화한 컬럼을 생성
나이별 인원 수 시각화
select age||'세'나이, lpad('■',count(*),'■') as bar_chart
from train2
group by age
order by age;

연령대 컬럼 생성
-- 연령대 컬럼 추가
alter table train3
add 연령대 varchar2(20);
-- 연령대 컬럼 update
begin
for i in (select age, case when age between 1 and 18 then '미성년'
when age between 19 and 34 then '청년'
when age between 35 and 49 then '장년'
when age between 50 and 64 then '중년'
else '노년' end 연령대
from train2)loop
update train2
set 연령대 = i.연령대
where age = i.age;
end loop;
end;
/
연령대별 인원 수 시각화
select 연령대||decode(연령대,'미성년','(1~18세)')||
decode(연령대,'청년','(19~34세)')||
decode(연령대,'장년','(35~49세)')||
decode(연령대,'중년','(50~64세)')||
decode(연령대,'노년','(65세~)') 연령대,
lpad('■',count(*)/10,'■') 인원수
from train2
group by 연령대
order by 인원수 desc;

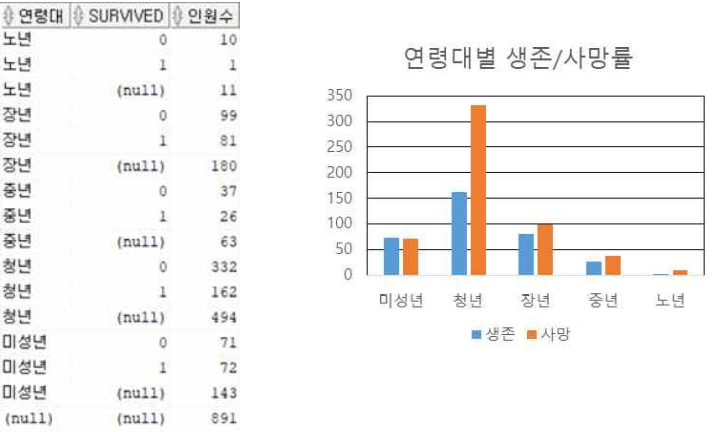
연령대별 생존/사망자 수
select 연령대, survived,count(*) as 인원수
from train2
group by rollup(연령대,survived);
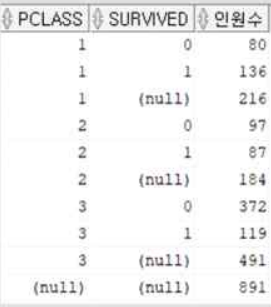
2.6. PCLASS(좌석등급) 별 생존/사망자 수 확인
select pclass, survived count(*) as 인원수
from train2
group by rollup(pclass, survived);
🙌 타이타닉 생존여부 예측
좌석등급, 신분, 연령대, 동승가족수 데이터를 이용해서 생존여부 예측 Update
예측을 위한 복사테이블 생성
-- 테이블 복사
create table forecast_table
as
select * from train2;
-- 예측테이블 survived(생존여부) 컬럼 NULL Update
update forecast_table
set survived = null;
생존여부 예측 Update
begin
for i in (select * from forecast_table) loop
if i.연령대 = '노년' then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '중년' and i.신분 = 'Mr' then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '중년' and i.sex = 'female' then
update forecast_table
set survived = 1
where passengerid = i.passengerid;
elsif i.연령대 = '미성년' and i.pclass = 3 then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '미성년' and i.pclass < 3 then
update forecast_table
set survived = 1
where passengerid = i.passengerid;
elsif i.연령대 = '미성년' and i.동승가족수 > 3 then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '장년' and i.pclass = 3 then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '장년' and i.pclass > 1 and i.sex = 'male' then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '장년' and i.pclass < 3 and i.sex = 'female' then
update forecast_table
set survived = 1
where passengerid = i.passengerid;
elsif i.연령대 = '청년' and i.신분 = 'Mr' then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
elsif i.연령대 = '청년' and i.pclass < 3 and i.sex = 'female' then
update forecast_table
set survived = 1
where passengerid = i.passengerid;
elsif i.연령대 = '청년' and i.pclass = 3 and i.신분 in('Mrs','Miss') then
update forecast_table
set survived = (select round(dbms_random.value(0,1)) from dual)
where passengerid = i.passengerid;
elsif i.연령대 = '청년' and i.pclass = 3 and i.동승가족수 >= 3 then
update forecast_table
set survived = 0
where passengerid = i.passengerid;
else
update forecast_table
set survived = 0
where passengerid = i.passengerid;
end if;
end loop;
end;
/
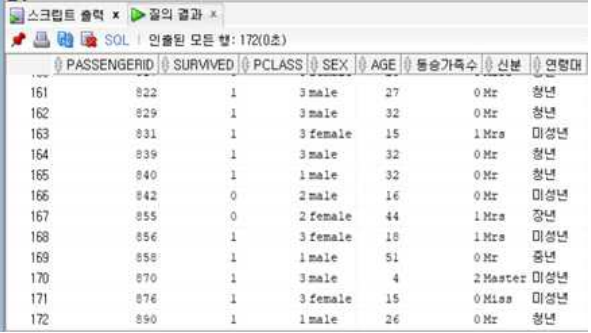
예측 정확도 확인
select *
from train2
minus
select *
from forecast_table;

😎 결론
- 먼저 SQL과 PL/SQL 만으로 머신러닝(?)을 해보니 상당히 무척이나 재미있었다.
- 예측 쿼리가 상당히 비효율적이고 억지스럽지만 조금이라도 더 높은 예측정확도를 위해 데이터를 deep하게 들여다보고 여러 생각을 하면서 파생변수 만드는 과정에서 너무 재미있었고 좋은 경험이었다.
- 머신러닝은 다른 좋~~은 언어들을 이용하자 ^^
댓글남기기